
Supervision
개요
root를 제외한 모든 actor은 부모 actor을 가짐
여기에서 부모 actor이 자기 자식 actor들의 supervisor 역할을 수행함
만약에, 자식 actor가 작업을 수행하는 도중에 exception 등 실패를 감지하게 되면 즉시 일시정지하고 자신의 supervisor에게 실패에 대한 메세지를 보내게 됨. 이러한 상황에서 supervisor에게는 4가지 선택지가 주어짐
자식 actor의 현재 상태를 유지하면서 재시작
자식 actor의 상태를 초기화하여 재시작
자식 actor을 영구적으로 정지
자식 actor에 대한 처리를 한 단계 위의 supervisor에게 위임
Actor클래스의preRestart의 기본 동작에서 모든 자식 actor을 종료시킴. 그것이 의도치 않은 동작이라면 해당 함수를 override할 필요성이 있음.실패 대응 function은 자식 actor에 대한 정보를 입력 받지 않기 때문에, 실패한 actor의 종류 별로 분류해서 다른 전략으로 대응하고 싶다면 레벨을 더 세분화하는 것 같이 구조적으로 나눠서 대응해야 함. 만약에 하나의 레벨에서 너무 많은 실패에 대응하려고 한다면 원인을 찾는게 어려워지기 때문
아카는 "parental supervision" 이라고 할 수 있음. 모든 actor은 부모 actor으로부터 만들어지고, 최상단 root actor은 라이브러리가 생성함.이러한 제약이 위와 같은 actor 구조를 형성해줌. 따라서 부모가 없는 actor나 외부에서 붙여진 actor는 존재하지 않도록 해야 함.
The Top-Level Supervisors
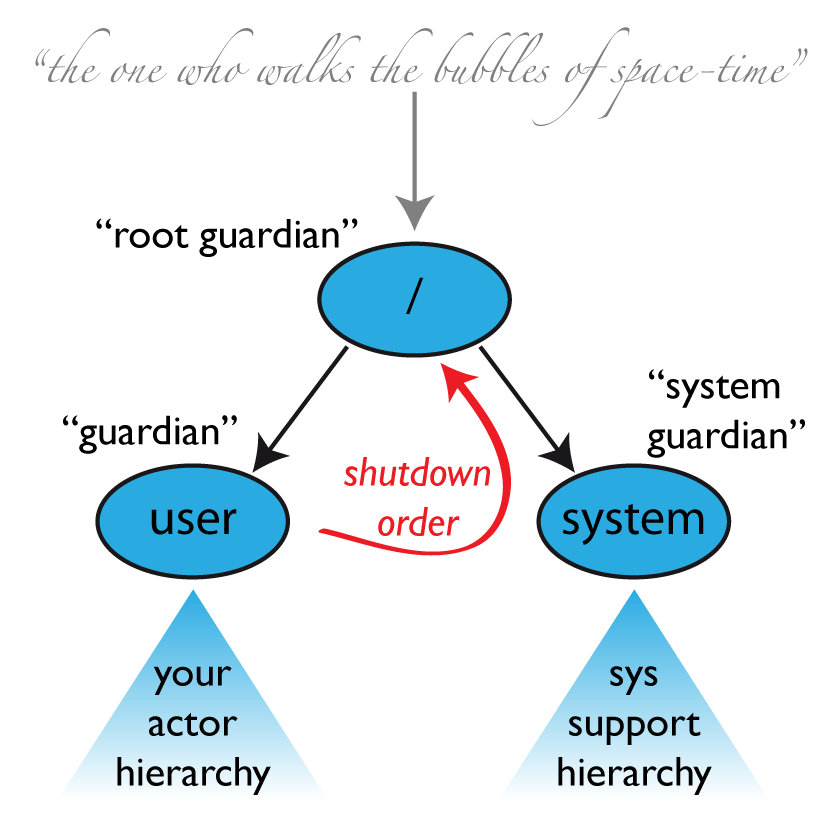
ActorSystem이 생성되면 위와 같은 최소한 3개의 actor을 가지고 있음
/user : The Guardian Actor
유저가 만든 모든 actor의 최상단 부모
system.actorOf()를 호출해서 만드는 모든 actor가 이 actor의 자식으로 들어감만약에 이 guardian이 종료되면 모든 일반적인 actor들이 종료된다고 할 수 있음
default supervisor strategy를 정할 때 활용할 수 있음
이 guardian이 어떤 실패를 root로 넘기게 되면 전체 시스템이 종료됨
/system : The System Guardian
체계적으로 shut-down을 진행하기 위해 존재하는 guardian
예를 들면 모든 actor가 종료될 때까지 logging이 활성화되어야 하는 상황
user guardian을 감시하다가
Terminated메세지를 받으면 shut-down을 시도root guardian이 감시하며
ActorInitializationException,ActorKilledException외에 모든Exception에 대해서 재시작 시도그 외의 모든 throwable가 넘어가게 되면 전체 시스템이 종료됨
/ : The Root Guardian
모든 "Top-level" actor들의 부모이며 superviser
SupervisorStrategy.stoppingStrategy을 통해 종류를 막론하고
Exception이 발생하면 자식을 종료하게 만듬
Restart
에러의 종류
특정 메세지를 받았을 때 발생하는 프로그래밍적 에러
메세지를 처리하기 위해 외부 자원을 사용할 때 발생하는 에러
actor의 내부 상태가 오염되어서 발생하는 에러
필요
특히 세 번째 종류의 에러는 actor의 내부 상태를 다시 깨끗하게 복구해야할 필요성이 있음
supervisor 자신과 다른 자식들이 오염에 영향을 받지 않는다면 오염된 자식만 재시작하는 것이 가장 좋음
순서
actor와 그 자식 actor들을 재귀적으로 모두 일시정지 (message를 더이상 처리하지 않도록 바꿈)
사라질 actor 인스턴스의
preRestarthook 호출 (모든 자식들에게 종료 요청을 보내고postStop호출하는게 기본값)종료 요청을 받은 모든 자식들이 종료될 때까지 대기. 이 또한 비동기 동작
주어진 factory에서 새로운 actor 인스턴스를 만듬
새로 생성된 인스턴스의
postRestart호출 (preStart호출하는게 기본값)3번에서 죽여지지 않은 모든 자식들에게 다시 재시작 요청을 보냄. 재시작 요청을 받은 자식들은 2번부터 재귀적으로 같은 동작을 수행
actor을 재시작함 (message 처리 시작)
Lifecycle Monitoring
재시작과 생성이 모두 내부적으로 이루어지기 때문에 오직 actor가 살아있는지 죽었는지에 대한 모니터링만 가능함
supervisor가 실패에 대해 반응하는 것과 달리 모니터링은 종료에 반응함
일반적으로는
Terminated메세지를 사용함ActorContext.watch(targetActorRef)를 호출해서 모니터링 시작ActorContext.unwatch(targetActorRef)를 호출해서 모니터링 종료
One-For-One Strategy vs. All-For-One Strategy
공통점
Exception이 발생할 때, 그 Exception의 타입을 특정 감시 수행 동작과 매핑
특정 자식이 종료되기 전까지 발생하는 실패의 허용치 제한
차이점
One-For-One은 실패가 발생한 해당 자식에게만 감시 수행 동작이 적용됨
All-For-One은 실패가 발생한 자식의 모든 형제까지 감시 수행 동작이 적용됨
주의점
All-For-One에서 한 자식을 직접 종료하면 다른 자식들에게 영향이 없음. 만약에 이러한 경우에도 모두 영향 받기를 원한다면 직접 watch를 써서 모니터링 해야 함
All-For-One에서 일회용 actor을 만들었다가 실패가 발생하면 다른 모든 영구적인 actor에도 영향을 미치게 됨. 이러한 경우에는 가운데에 supervisor를 추가로 두는 것이 좋음.
Last updated